State-based consistent messaging
by Tomek Masternak, Szymon PobiegaIn the previous posts, we described consistent messaging and justified its usefulness in building robust distributed systems. Enough with the theory, it’s high time to show some code! First comes the state-based approach.
Context
State-based consistent messaging comes with two requirements:
- “Point-in-time” state availability - it’s possible to restore any past version of the state.
- Deterministic message handling logic - for a set state and input message every handler execution gives the same result.
Idea
Given the requirements, the general idea of how to achieve consistent message processing is quite simple. When dealing with a message duplicate we need to make sure the handler operates on the same state as when the message was first processed. With this and deterministic handler logic (handler being a pure function), we ensure that processing of a message duplicate results in identical state changes and output messages.
Here is a pseudo-code implementation:
1foreach(var msg in Messages)
2{
3 var (state, version) = LoadState(msg.BusinessId, msg.Id);
4
5 var outputMessages = InvokeHandler(state, message);
6
7 if(state.DuplicatedMessage == false)
8 {
9 StoreState(state, version)
10 }
11
12 Publish(outputMessages);
13}First, we load a piece of state based on BusinessId and Id of the message. LoadState returns either the newest version of the state or if the message is a duplicate, a version just before the one when the message was first processed. In other words, LoadState makes sure to recreate the proper version of the state for duplicates. These two scenarios (new vs. duplicate message) are distinguished based on DuplicatedMessages flag. Based on its value the state update is either applied or skipped.
It’s worth noting that message publication comes last and it’s for a reason. Optimistic concurrency control based on the version argument makes sure that in case of a race condition processing will fail before any ghost messages get published.
Implementation
Listings below show only the most interesting parts of the implementation. Full source code can be found in exactly-once repository.
State management
With the general idea of the solution in place let’s look at the implementation details. For storing the state we use Streamstone library that provides event store API on top of Azure Table Storage.
One of the questions that we still need to answer is how to store the “message-id to state version” mapping. This is done by storing message id as a property of an event for each entry in the stream.
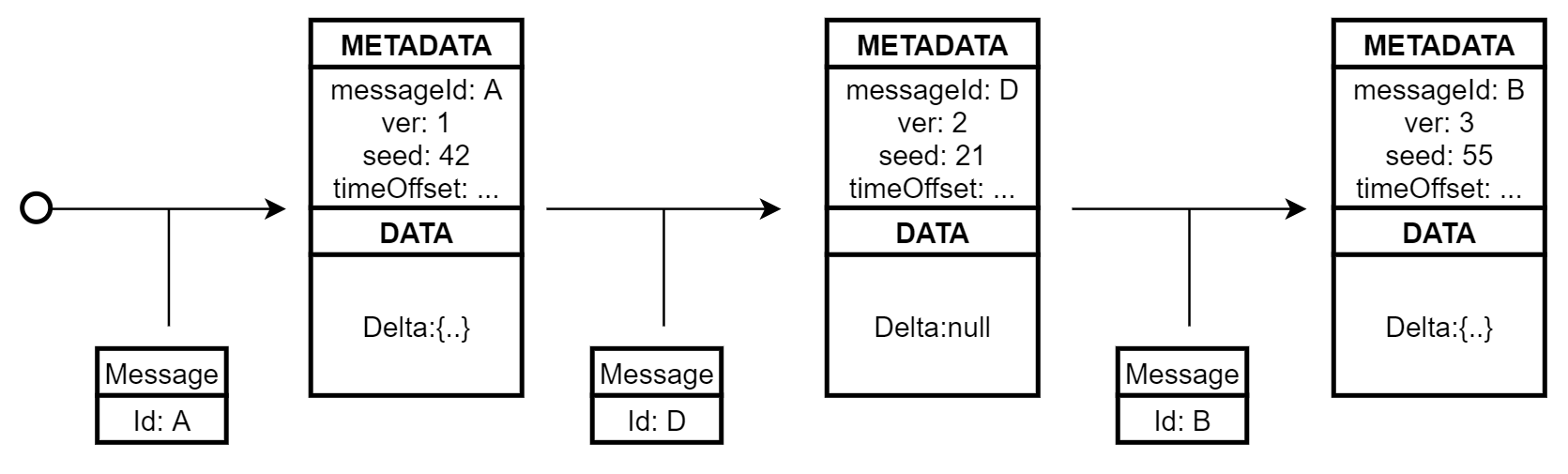
State stream for a [A, D, B] message processing sequence
When a new message gets processed a new version of the state is stored as an event that includes additional message metadata. These include a message identifier that enables duplicates detection and restoring an appropriate version of the state. In LoadState when reading events from the stream the metadata field is checked to see if the current message identifier matches the one already captured. If so the process stops before reaching the end of the stream:
1// `ReadStream` iterates over a stream passing each event to
2// the lambda. Iteration stops when reaching the end of the
3// stream or when lambda returns `false`.
4var stream = await ReadStream(partition, properties =>
5{
6 var mId = properties["MessageId"].GuidValue;
7 var nextState = DeserializeEvent<THandlerState>(properties);
8
9 if (mId == messageId)
10 {
11 isDuplicate = true;
12 }
13 else
14 {
15 state = nextState;
16 }
17
18 return isDuplicate;
19});The duplicate detection requires that input message id is always captured, even if handling logic execution results in no state changes - ShootingRange handler logic for FireAt message is a good example of such case.
Versioning of the state doesn’t surface to the business logic and the state is represented as POCO e.g.:
1public class ShootingRangeData
2{
3 public int TargetPosition { get; set; }
4 public int NumberOfAttempts { get; set; }
5}Processing logic
At the business logic level the message handling doesn’t require any infrastructural checks to ensure consistency:
1public void Handle(IHandlerContext context, FireAt command)
2{
3 if (Data.TargetPosition == command.Position)
4 {
5 context.Publish(new Hit
6 {
7 Id = context.NewGuid(),
8 GameId = command.GameId
9 });
10 }
11 else
12 {
13 context.Publish(new Missed
14 {
15 Id = context.NewGuid(),
16 GameId = command.GameId
17 });
18 }
19
20 if (Data.NumberOfAttempts + 1 >= MaxAttemptsInARound)
21 {
22 Data.NumberOfAttempts = 0;
23 Data.TargetPosition = context.Random.Next(0, 100);
24 }
25 else
26 {
27 Data.NumberOfAttempts++;
28 }
29}That said, line 7 where Hit message id is generated deserves more discussion. We are not using a standard library call to generate a new Guid value for a reason. As Guid generation logic is nondeterministic from the business logic perspective we can’t use it without breaking the second requirement. We need to make sure that the re-processing of a message results in identical output messages (including their identifiers). Some kind of seed data is needed to enable that - in our example, the input message id plays that role and gets passed to the context just before handler execution:
1static List<Message> InvokeHandler<THandler, THandlerState>(...)
2{
3 var handler = new THandler();
4 var handlerContext = new HandlerContext(inputMessage.Id);
5
6 ((dynamic) handler).Data = state;
7 ((dynamic) handler).Handle(handlerContext, inputMessage);
8
9 return handlerContext.Messages;
10}Guid generation scenario touches on a more general case. The same kind of problem exists when using random variables, time offsets or any other environmental variables that might change in between handler invocations. To handle these cases we would need to capture additional invocation context in the event metadata (as shown on the diagram) and expose utility methods on the IHandlerContext instance passed to the business logic.
In summary, for the handler to be deterministic it needs to operate over the business state and/or additional context data that gets captured during message processing.
Mind the gap
The implementation of state-based consistent messaging has some gaps that require mentioning. First, in most real-world applications the state version storage requires clean-up. At some point, the older versions are no longer needed e.g. after n number of days and should be removed. This most likely requires some background clean-up process making sure this happens.
Secondly, the approach to storing the state has been chosen for its clarity. In some production scenarios, this might require optimizations from the storage consumption perspective e.g. storing state deltas instead of the whole snapshots and removing deltas for versions that already had their messages published.
Finally, the decision to hide state history from the business logic might not be necessary. In systems using event sourcing for deriving the state, the state-based approach might be integrated into persistence logic.
Azure Durable Functions is one example of a technology using a similar approach and good case study of how some of the above problems could be solved.
Pros and cons
We already mentioned the requirements needed for the state-based approach to message consistency. It’s time to clarify are the advantages and disadvantages of this approach.
Advantages:
- No infrastructural concerns in the business logic.
- Flexible de-duplication period based on the stream truncation rules.
- Can be piggy-backed on event sourcing.
Disadvantages:
- Ensuring deterministic logic requires attention - making sure logic is deterministic might be error-prone.
- Managing business logic changes - changing business logic needs to be able to cope with historical versions of the state.
- Stream size is proportional to the number of messages processed - even if messages do not generate state changes.
Summary
This post covers the state-based approach to consistent messages. Side-effects based is the one we will have a closer look next.
Have any questions? Make sure to ping us on Twitter!